
Spade is a hardware description language inspired by modern software languages.
- Strong and expressive type system to catch bugs early
- First-class pipelines
- Zero-cost Abstractions for hardware
- Helpful compiler with great error messages
- Cute mascot
// Compute the dot product of two arrays of any size
Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline.(3) dot_product<#uint N>(
clk: clock,
rst: bool,
a: [int<16>; N],
b: [int<16>; N],
) -> int<32> {
let is used to define a variable. Spade infers the type of most variables from context, but you can also specify the type with : <type> before the =. products = a
.zip(b)
.map(fn |...| is a lambda function, a function written in-line to be passed to other functions to control their behaviour.
The arguments to the function are the part between the ||
(a, b)| a * b)
reg * N; creates N Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline. registers with no computation between them. This is typically used when waiting for another Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline., or to insert several registers at the end of a computation to be re-timed into the computation by the synthesis tool.
// Return the sum of the products
The last value in the block is the return value of the whole unit. Here, we're returning the sum of the products
}
Reason about timing with Pipelines
Pipelines are a first class construct in Spade. By encoding the latency in the language, they make re-timing and re-pipelining trivial.
Pipeline stages are separated by reg, and the compiler inserts the required intermediate registers to keep all signals in sync.
When nesting pipelines, the compiler will tell you when you are accessing values too early and ensure that all signals are in sync.
// Compute x^3*c[0] + x^2*c[1] + x*c[2] + c[3]. One
// clock cycle latency for each multiplier and adder.
// Can be adjusted by just adding or removing `reg`s
Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline.(4) polynomial(clk: clock, x: int<18>, c: [int<18>; 4])
-> int<74> {
let is used to define a variable. Spade infers the type of most variables from context, but you can also specify the type with : <type> before the =. x_squared = x * x;
reg; is used in a Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline. to separate stages. When you refer to a variable defined above a reg; statement below a reg; statement you refer to a registered version of the original value.
Registers defined with an explicit clock (reg(clk)) are used for state registers both inside and outside pipelines.
let is used to define a variable. Spade infers the type of most variables from context, but you can also specify the type with : <type> before the =. x_cubed = x_squared * x;
reg; is used in a Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline. to separate stages. When you refer to a variable defined above a reg; statement below a reg; statement you refer to a registered version of the original value.
Registers defined with an explicit clock (reg(clk)) are used for state registers both inside and outside pipelines.
let is used to define a variable. Spade infers the type of most variables from context, but you can also specify the type with : <type> before the =. p3 = c[0] * x_cubed;
let is used to define a variable. Spade infers the type of most variables from context, but you can also specify the type with : <type> before the =. p2 = c[1] * x_squared;
let is used to define a variable. Spade infers the type of most variables from context, but you can also specify the type with : <type> before the =. p1 = c[2] * x;
let is used to define a variable. Spade infers the type of most variables from context, but you can also specify the type with : <type> before the =. p0 = c[3] * 1;
reg; is used in a Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline. to separate stages. When you refer to a variable defined above a reg; statement below a reg; statement you refer to a registered version of the original value.
Registers defined with an explicit clock (reg(clk)) are used for state registers both inside and outside pipelines.
// sext is sign extension. Spade never implicitly casts
// integer widths to avoid surprises
let is used to define a variable. Spade infers the type of most variables from context, but you can also specify the type with : <type> before the =. result = (p3 + sext(p2)) + sext(p1 + p0);
reg; is used in a Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline. to separate stages. When you refer to a variable defined above a reg; statement below a reg; statement you refer to a registered version of the original value.
Registers defined with an explicit clock (reg(clk)) are used for state registers both inside and outside pipelines.
result
}Powerful Type System
The type system in Spade is similar to that of Rust, Haskell, and Scala, allowing assumptions and invariants to be encoded directly in the language. This greatly simplifies integration of different modules and makes refactoring easier.
With enums, you can model things like FSMs, commands, and instructions, where data is not always available. The compiler will ensure that you never read invalid data.
With ports, you can group related input and output signals into one unit to be passed along to modules that need them. The compiler ensures that all signals are written exactly once.
Types in Spade can be generic over any type, not just parameterized by integers allowing you to easily work with complex types.
// Command to be used in a memory for either reading or writing
// data. Generic over any type T which can be inferred from where
// this is used
enum MemoryCommand<T> {
Read { addr: uint<16> },
Write { addr: uint<16>, data: T },
}
// A memory port from which values can be either written or read
struct MemoryPort<T> {
addr: inv uint<16>,
// The `Option<T>` type represents a value of type `T` along with
// a `valid` signal. The compiler ensures that the data is only
// read when valid
write: inv Option<T>,
read_value: T,
}
impl MemoryPort<T> {
// A method that drives the memory port based on the specified cmd.
// The command being an option means it is not always present.
// When used with block-RAM, the access latency is 1 clock cycle,
// hence the Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline..
Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline.(1) with_command(self, clk: clock, cmd: Option<MemoryCommand>)
-> Option<T>
{
// Some and None are the Valid/Invalid cases in the Option type
let is used to define a variable. Spade infers the type of most variables from context, but you can also specify the type with : <type> before the =. (is_read, addr, write) = match cmd {
None => (false, 0, None),
Some(MemoryCommand::Read$(addr)) => (true, addr, None),
Some(MemoryCommand::Write$(addr, data)) => (false, addr, data),
};
set self.addr = addr;
set self.write = write;
reg; is used in a Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline. to separate stages. When you refer to a variable defined above a reg; statement below a reg; statement you refer to a registered version of the original value.
Registers defined with an explicit clock (reg(clk)) are used for state registers both inside and outside pipelines.
if is_read { Some(self.read_value) } else { None }
}
}Fearless Refactoring for Agile Design
With a powerful type system and pipelines it becomes easy to make large scale changes to a project without fear of breaking existing code.
The type system helps you accomodate new feature requirements in an agile workflow, and pipelining allows you to improve timing without affecting functionality.
Extensible With Your Abstractions
The type system is powerful enough for you to build your own abstractions for your application domain.
The Option type in the standard library can be used to build Ready/Valid handshaking which in turn can be used to build an Ethernet library, or why not a logic analyzer in less than 100 lines of code.
// Part of a logic analyzer that splits samples up into individual bytes,
// adds headers and footers to packets, and sends the resulting packets
// over UART.
Rv(data_in, full.1)
.inst is required when instantiating entities, units with state, as opposed to fn which are combinational, or pure in software terms. fifo_buffer::<SampleBuffer>(clk, rst)
.read_empty(empty.1)
.data
.inst is required when instantiating entities, units with state, as opposed to fn which are combinational, or pure in software terms. map(fn |...| is a lambda function, a function written in-line to be passed to other functions to control their behaviour.
The arguments to the function are the part between the ||
sample| sample.to_bytes())
.inst is required when instantiating entities, units with state, as opposed to fn which are combinational, or pure in software terms. into_element_stream(clk, rst)
.inst is required when instantiating entities, units with state, as opposed to fn which are combinational, or pure in software terms. map(fn |...| is a lambda function, a function written in-line to be passed to other functions to control their behaviour.
The arguments to the function are the part between the ||
byte| { Escaped::Yes(byte) })
.inst is required when instantiating entities, units with state, as opposed to fn which are combinational, or pure in software terms. add_headers(clk)
.inst is required when instantiating entities, units with state, as opposed to fn which are combinational, or pure in software terms. escape_bytes$(
clk,
rst,
escapees: [0xff, 0xfe],
escape_fn: fn |...| is a lambda function, a function written in-line to be passed to other functions to control their behaviour.
The arguments to the function are the part between the ||
byte| byte ^ 0x80,
escape_prefix: 0xfe,
)
.inst is required when instantiating entities, units with state, as opposed to fn which are combinational, or pure in software terms. into_uart( ... );Predictable and Performant Results
Spade is not High Level Synthesis. The underlying abstraction is still RTL meaning you have full control over the hardware that gets generated.
The abstractions that Spade provide have zero or very little performance overhead If you need that final bit of precise control you can always locally unwrap the abstractions and describe exactly what you need, without affecting the rest of your code base.
// This dot product example from the top of the page may look magic
Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline.(1) dot_product<#uint N>( ... ) -> int<32> {
let is used to define a variable. Spade infers the type of most variables from context, but you can also specify the type with : <type> before the =. products = a
.zip(b)
.map(fn |...| is a lambda function, a function written in-line to be passed to other functions to control their behaviour.
The arguments to the function are the part between the ||
(a, b)| a * b)
reg * N; creates N Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline. registers with no computation between them. This is typically used when waiting for another Defines a pipeline. The number in in the parentheses is input-to-output latency of the pipeline., or to insert several registers at the end of a computation to be re-timed into the computation by the synthesis tool.
products.sum()
}
// But it compiles to the following which has a one-to-one mapping
// to the generated Verilog
entity dot_product(...) {
reg(clk) products = [a[0] * b[0], a[1] * b[1], ...]
reg(clk) products_s2 = products;
reg(clk) products_s3 = products;
products_s3[0] + products_s3[1] ...
}Purpose Built Tooling
Spade comes with all the tools you need. The build tool, swim, manages your project and allows you to use dependencies from the open source ecosystem, or internal to your organization.
The language has text-editor integration via the language server protocol, and there is a work in progress documentation generator.
For debugging, the Surfer waveform viewer was built specifically for Spade to simplify development when complex types are involved.
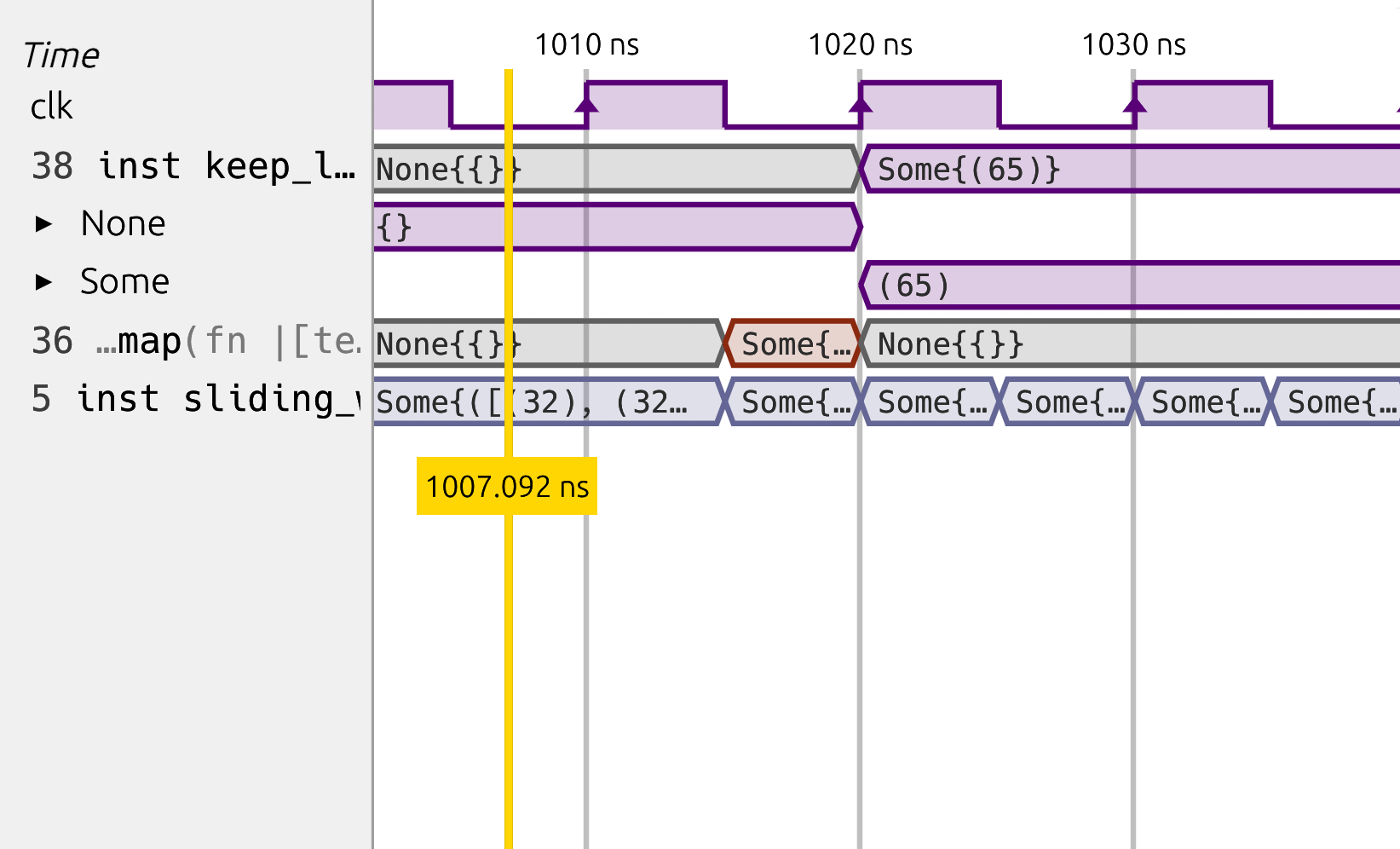
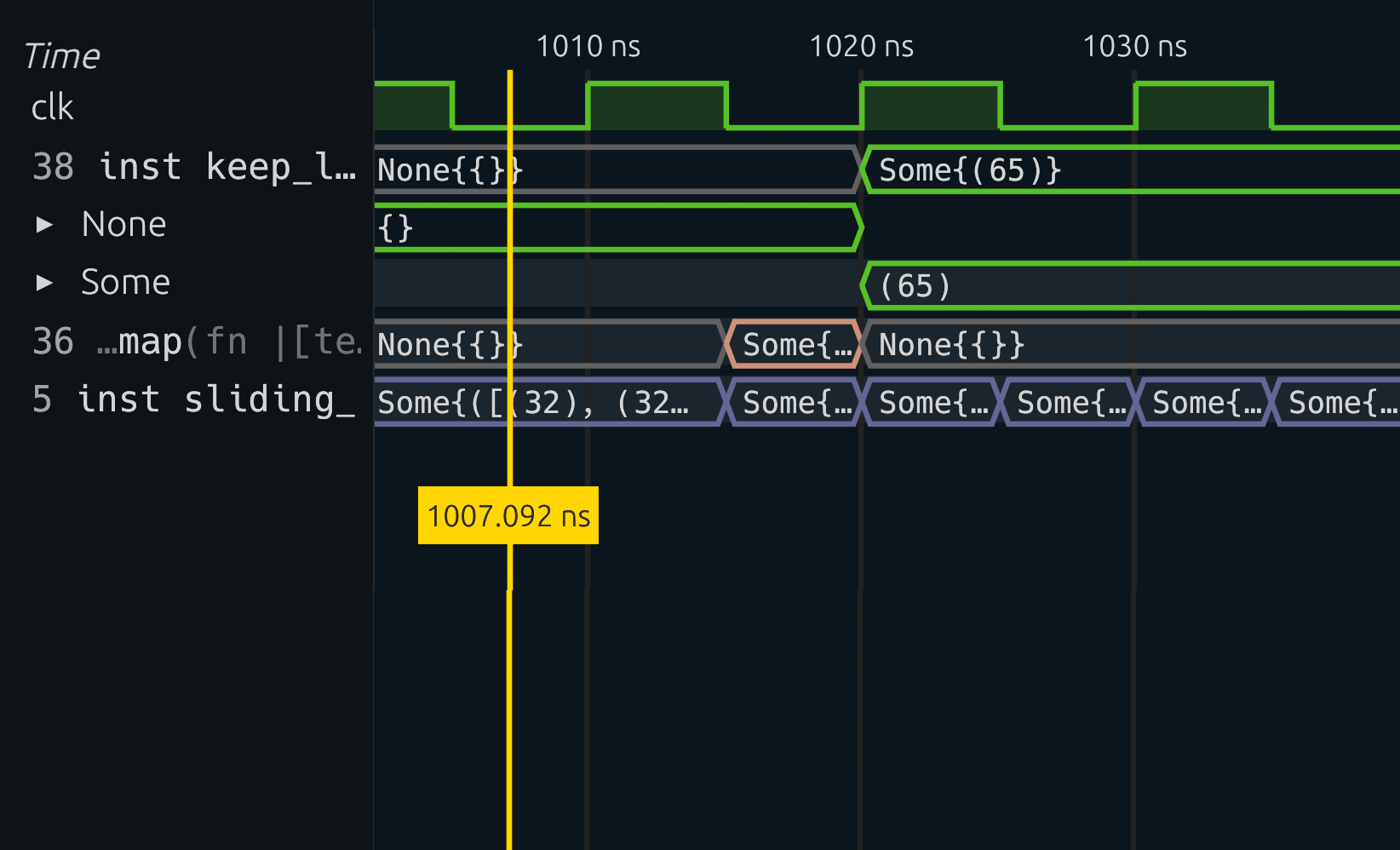
Easy Verilog Interop
You do not have to switch to Spade all at once, you can re-use existing Verilog code from Spade, and since the compiler emits Verilog, you can instantiate Spade from existing Verilog code to use it in a bigger project.
// Example from Spade bindings for the Berkely HardFloat library.
// Both signals and parameters are exposed to Spade
#[no_mangle(all)]
extern entity recFNToFN <
#uint expWidth,
#uint sigWidth
>(
in: uint<{expWidth + sigWidth + 1}>,
out: inv uint<{expWidth + sigWidth}>
);Meet Phoebe
Phoebe (she/her) is a Spadefish. She’s the logo and mascot of the language, very cute, and the reason all the tools around Spade are ocean themed!

Convinced?
If you have questions or want to join the community, join the discord or matrix channels. (They are bridged, pick your favourite platform!)

 Matrix
MatrixPublications
-
Frans Skarman, Gustav Sörnäs Oscar Gustafsson. Spade – A Modern Hardware Description Language. January 2026. In: ACM Trans. Reconfig. Technol. Syst., Vol. 1, No. 1.
-
Frans Skarman Improved Tooling for Digital Hardware Development: Spade, Surfer, and more. August 2025. PhD Thesis
-
Frans Skarman, Lucas Klemmer Oscar Gustafsson Daniel Große. Enhancing Compiler-Driven HDL Design with Automatic Waveform Analysis. September 2023. In: Forum on specification & Design Languages (FDL).
-
Frans Skarman, Oscar Gustafsson. Spade: An Expression-Based HDL With Pipelines. April 2023. In: 3rd Workshop on Open-Source Design Automation (OSDA).
-
Frans Skarman, Oscar Gustafsson. Abstraction in the Spade Hardware Description Language. March 2023. In: 3rd Workshop on Languages, Tools, and Techniques for Accelerator Design (LATTE).
-
Frans Skarman, Oscar Gustafsson. Spade: An HDL Inspired by Modern Software Languages. August 2022. In: 32nd International Conference on Field-Programmable Logic and Applications (FPL).
Talks
-
Frans Skarman Guest lecture at CSE 228A - Agile Hardware Design, Spring 2025, UC Santa Cruz. May 2025.
-
Frans Skarman Spade - An HDL Inspired by Modern Software Languages. May 2024. At: LatchUp 2024.
A few more miscellaneous presentations are available on the Spade YouTube Channel
Develoment
Spade is developed as an open source project with significant contributions from the community ❤️
The project is currently maintained in the AEMY group at Munich University of Applied Sciences.
![]()
The project has received funding from NGI Zero Core via NLNet

Development of Spade started in the ELDA group at Linköping University.
